
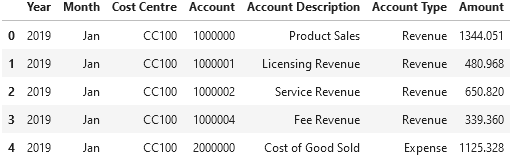
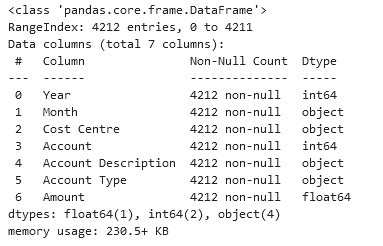
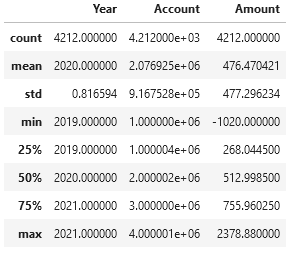
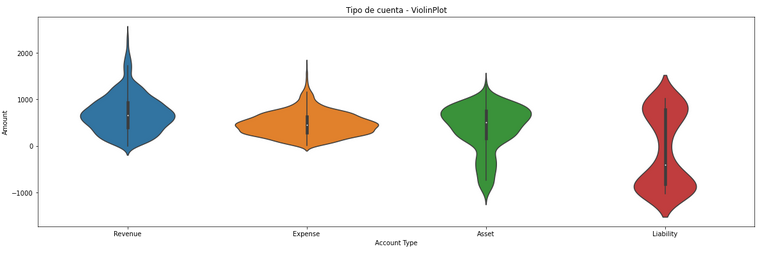
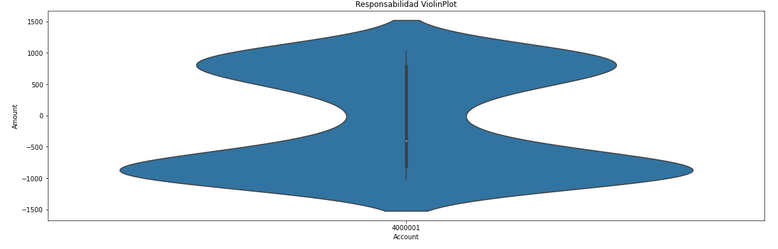
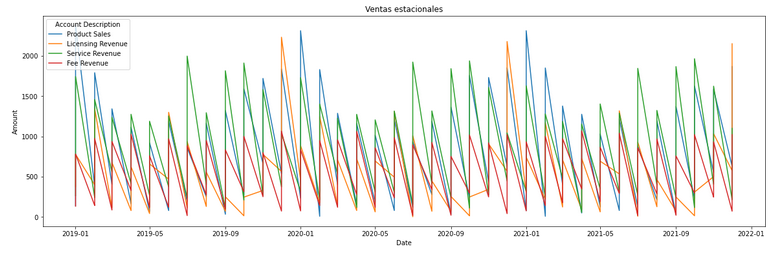
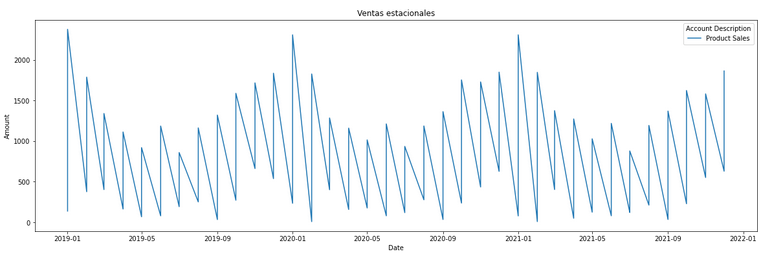





Una paciente sale de consulta con la orden de una resonancia. El médico la generó…

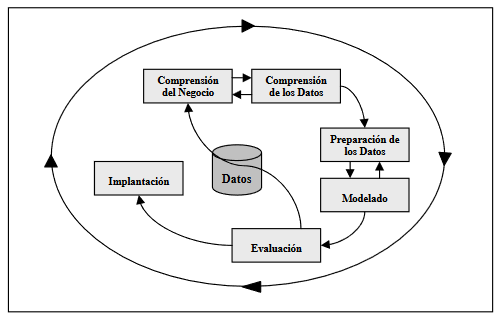
Cuando hablamos de un sistema de historia clínica, normalmente pensamos en la atención médica, la…

La transformación digital en salud suele presentarse como el camino para optimizar procesos, mejorar la…

