
Por mucho tiempo el término minería de datos ha sido relacionado con las técnicas de Inteligencia Artificial (AI) y aprendizaje de máquina que permite extraer nueva información útil basándose en la detección de patrones entre los datos almacenados.
El término KDD hace referencia a las siglas de Knowledge Discovery in Databases, en español el “Descubrimiento de Conocimiento en Bases de Datos”, fue mencionado por primera vez por Piatetsky-Shapiro en 1989 para describir el proceso por medio del cual se extraía de una base de datos información útil hasta ahora desconocida para quien realizaba el proceso.
Involucra un trabajo extenso en minería de datos como uno de sus pasos más importantes. El KDD (Descubrimiento de Conocimiento en Bases de Datos) implica un conjunto de etapas definidas para el tratamiento de los datos antes de aplicar las diferentes técnicas de minería de datos en la búsqueda de patrones ocultos en ellos para finalmente hacer el análisis de los patrones encontrados, con el objeto es brindar nueva información y conocimiento.
Hasta hace unos años minería de datos y KDD (Descubrimiento de Conocimiento en Bases de Datos) eran mencionadas indiscriminadamente para referirse a la extracción de patrones de las variables en una base de datos. Hasta hace poco, menos de 10 años, algunos investigadores comenzaron a utilizar el término KDD (Descubrimiento de Conocimiento en Bases de Datos) para referirse a la extracción de conocimiento proveniente de bases de datos como un macro proceso, mientras que minería de datos era catalogada como el mecanismo de aplicación de algoritmos para extraer patrones presentados por los mismos.
Se dice entonces que KDD (Descubrimiento de Conocimiento en Bases de Datos) es el proceso para la identificación de patrones válidos, nuevos, útiles y sobre todo comprensibles, que conlleva al descubrimiento de nuevo conocimiento. En cambio, la minería de datos se refiere a solo una de las etapas de dicho proceso, considerada por muchos como la más importante.
Esta técnica de extracción de información es utilizada ampliamente en muchas áreas; por ejemplo, en economía se utiliza para descubrir tendencias del mercado, en la salud para realizar prevención o anticipar de diagnósticos, en mercadeo tiene gran importancia para encontrar patrones entre los tipos de clientes y sus tendencias al momento de seleccionar productos, en el área de seguridad Informática las entidades financieras han logrado importantes avances en la detección anormal del comportamiento de las variables para la generación de alertas de fraude, entre otros.
Actualmente, los sistemas de información cuentan con bases de datos muy robustas. La capacidad de almacenamiento se ha incrementado en los últimos años de la misma manera que lo han hecho los datos y las variables de información en las compañías, entes gubernamentales, universidades y demás instituciones. Esto ha hecho que el análisis de la información almacenada sea complejo para quienes requieren tomar decisiones prácticas con base en los datos.
El uso de herramientas que permiten extraer información de las bases de datos ha tomado fuerza en los campos de investigación como la estadística, el aprendizaje de máquina, las bases de datos, entre otras.
En el campo de la salud, los estudios estadísticos de minería de datos y de adquisición de información en bases de datos han generado importantes contribuciones para el área del cuidado de dicho sector, en el cual las oportunidades de construcción de conocimiento basado en la información de prácticas clínicas son de vital importancia para las intervenciones futuras que se puedan realizar a los pacientes.
Como mencionamos anteriormente, el almacenamiento de datos en los diferentes sistemas de información ha venido incrementándose de manera dramática, alejándose de las posibilidades humanas para extraer información útil de manera eficiente. Por este motivo se hace necesario el uso de un método que ayude a las personas a interpretar la información almacenada en estas enormes bases de datos y poder extraer nuevo conocimiento.
El KDD (Descubrimiento de Conocimiento en Bases de Datos) tiene 9 pasos y su secuencia es importante para la obtención de los resultados esperados. En algunos casos puede llegar a ser necesario regresar tras la identificación de alguna oportunidad de mejora en el tratamiento de los datos.
9 pasos del KDD (Descubrimiento de Conocimiento en Bases de Datos)
Los 9 pasos del KDD (Descubrimiento de Conocimiento en Bases de Datos) son:
- Identificación del problema y del dominio de trabajo.
- Creación del conjunto de datos.
- Pre-procesamiento de los datos.
- Reducción de datos y proyección.
- Formulación de los objetivos del PROCESO KDD (Descubrimiento de Conocimiento en Bases de Datos)
- Exploración de análisis, modelo y selección de la hipótesis.
- Minería de datos
- Interpretación de los patrones encontrados
- Descubrimiento de nuevo conocimiento
En la siguiente imagen se presenta de manera resumida los pasos o etapas para la obtención de nuevo conocimiento en bases de datos.
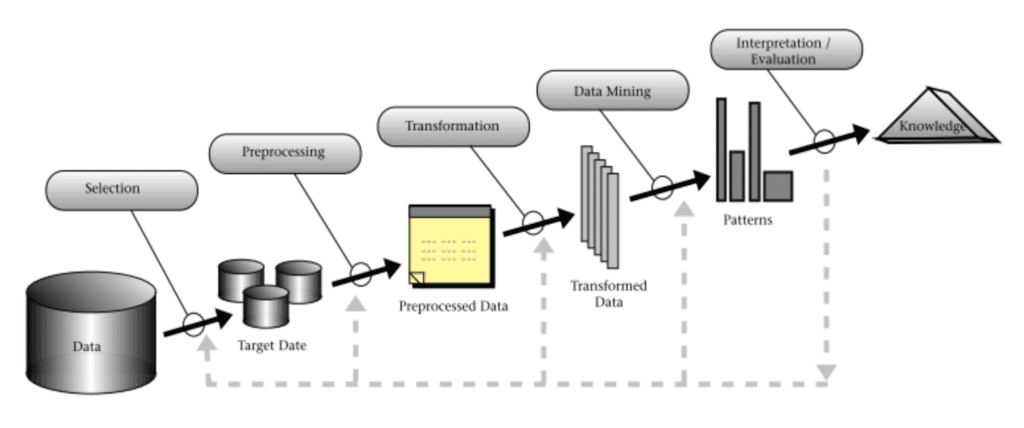
Fuente: Fayyad, U. (1996)
Referencias bibliográficas
Chen, Z., & Zhu, Q. (Aug. de 1998). Query construction for user-guided knowledge discovery in databases. Information Sciences, 109(1–4), 49–64.
Ester , M., Kriegel, H. P., Sander, J., & Xu, X. (1996). A density-based algorithm for discovering clusters in large spatial databases with noise. In 2nd Int. Conf. on Knowledge Discovery and Data Mining (KDD 96), (págs. 226-231). Portland, USA.
Ester, M., Frommelt, A., Kriegel, H., & Sander, J. (2000). Spatial data mining: Database primitives, algorithms and efficient DBMS support. 4(2-3), 193–216.
Fayyad, U. (1996). Data mining and knowledge discovery: making sense out of data. IEEE Computer Society, 11(5), 20–25.
Fayyad, U., & Stolorz, P. (1997). Data mining and KDD: Promise and challenges. Future Generation Computer Systems, 13(2–3), 99–115.
Fayyad, U., & Uthurusamy, R. (1996). Data mining and knowledge discovery in databases. (39, Ed.) Communications of the ACM.
Goodwin, L., Vandyne, M., Lin, S., & Talbert, S. (2003). Data mining issues and opportunities for building nursing knowledge. Journal of Biomedical Informatics, 36(4–5), 379–388.
Han, J., Nishio, S., Kawano, H., & Wang, W. (1998). Generalization-based data mining in object-oriented databases using an object cube model. Data & Knowledge Engineering, 25(1-2), 55–97.
Köksal, G., Batmaz, I., & Testik, M. C. (2011). A review of data mining applications for quality improvement in manufacturing industry. Expert Systems with Applications, 38(10), 13448–13467.
Magnisalis, I., Demetriadis, S., & Karakostas, A. (2011). Adaptive and intelligent systems for collaborative learning support: A review of the field. IEEE Transactions on Learning Technologies, 4(1), 5–20.




